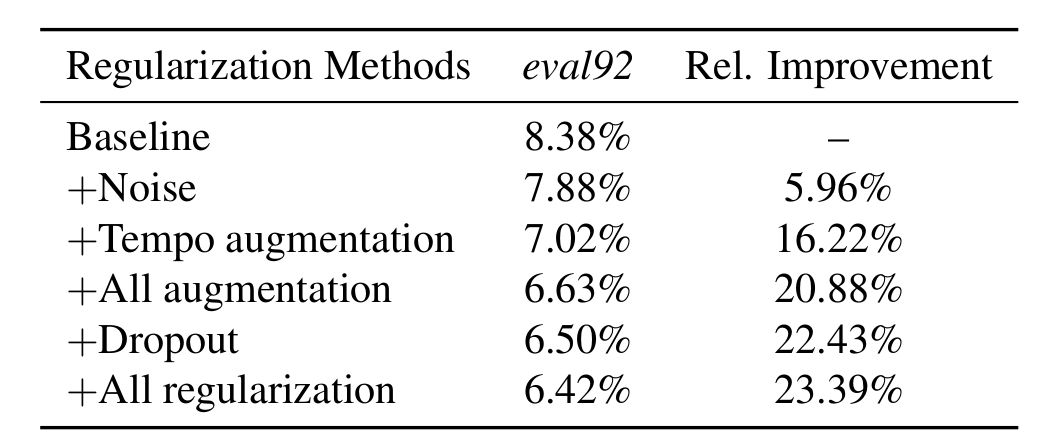
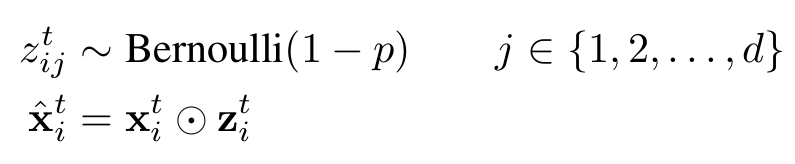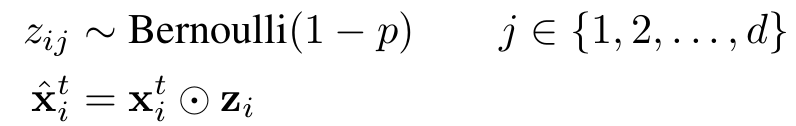End-to-end speech recognition improved rule techniques For end-to-end models, the performance of the model can be improved through data enhancement and Dropout methods. The same is true in speech recognition. Previously, I had not written data enhancement techniques for speech recognition tasks. Recently, we have done a large-scale speech recognition practice and found that data enhancement is a disaster for small data sets. Of course, If you have a large database of tens of thousands of hours of speech, and you can also include different accent styles across the country, then data reinforcement theory can also play a icing on the cake. Today based on this article from Salesforce Research and his usual practical experience, to share the skills of the voice recognition task in addition to the model can improve performance. In this paper, the audio is modified by a slight perturbation to the speed, pitch, volume, and time alignment of the audio, and by adding Gaussian white noise. The article also discusses the use of each layer of neural network. The effect of dropout. The experimental results show that the performance of the speech recognition model can be improved by more than 20% compared to the baseline system on the WSJ database and the LibriSpeech database by using the data enhancement technology together with the dropout. From the results, these regularization techniques can be used for speech recognition. The performance improvement is of great help. Let's take a look at the model based on which the authors practice these data enhancement techniques. The end-to-end model used in this paper is very close to the Deep Speech2 (DS2) proposed by Baidu. As shown in the above figure, the original feature data first passes through a convolutional layer with a larger convolution kernel. The larger benefit of the convolution kernel is the original The feature is reduced in dimension. After dimension reduction, five residuals are connected to each other, and each residual area is composed of a batch normalized layer, a channel-wise convolution layer, and a 1×1 convolution layer, and passes through the relu. The activation function, immediately followed by four bidirectional GRU networks, finally obtains the target probability distribution through the full connection layer, and adopts the end-to-end CTC loss function as an objective function, and uses a stochastic gradient descent algorithm to optimize. The innovations made here compared to DS2 are mainly channel-wise separable convolutional layers, which are actually depth-wise separable convolutional layers. Compared with conventional convolutions, they have the advantages of good performance and reduced parameters. The difference in quantity can be seen by the following example (for an introduction to separable convolutions, you can search xception for this article): Suppose now that a convolution is done, the input depth is 128 and the output depth is 256; conventional operations use a convolution kernel 3×3 to convolve, then the number of parameters is 128×3×3×256=294912; depth-wise can be Deconvolution operation is to set depth multiplier=2 to get a depth of 2 × 128 middle layer, and then through a 1 × 1 convolution layer dimension to reduce the depth to 256, the number of parameters is 128 × 3 × 3 × 2 + 128 × × 2 × 1 × 1 × 256 = 67840, you can see that compared to conventional convolution, the parameters decreased by 77%; In addition to the use of depth-wise separable convolutional layers, residual joins and the use of batch normalization techniques at each level contribute to the training, with a total network of approximately 5 million parameters. If the parameters are too large, the problem of overfitting is likely to occur. To avoid overfitting, the author tried to explore two techniques of data enhancement and dropout to improve the performance of the system. Data enhancement Prior to this, Hinton had proposed to use Vocal Tract Length Perturbation (VTLP) method to improve the performance of speech recognition. The specific method is to apply a random distortion factor to the spectral features of each audio during the training phase. Through this practice, Hinton The performance of the test set on the TIMIT small data set was improved by 0.65%. VTLP is a data enhancement technique based on the feature level, but later it was also found that the performance improvement brought about by changing the speed of the original audio is better than that of VTLP. . However, the speed of the audio speed actually affects the pitch, so increasing the speed of the audio inevitably increases the pitch of the audio. Conversely, reducing the speed of audio will make the tone of the audio smaller. Therefore, only by adjusting the speed can not produce fast and low-pitched audio, which makes the audio diversity is reduced, the performance of the speech recognition system is limited. In this article, the author hopes to enrich the changes of audio through data enhancement and increase the quantity and diversity of data. The author then takes control of the speed of audio through two separate variables, namely, tempo and pitch, namely, rhythm and tone. High, the adjustment of the rhythm and pitch of the audio can be done through the voice Swiss sword-SOX software. In addition to changing tempo and pitch, the author added Gaussian white noise, changed the volume of the audio, and randomly distort the sample points of some of the original audio. 2. dropout Dropout is Hinton's technique to prevent over-fitting of deep neural networks. It does this by training the neural network to randomly change the input of certain neurons to zero. The formula is shown below. The Bernoulli distribution with a probability of 1-p is then multiplied with the input of the neuron to obtain the input after the dropout; in the reasoning phase, we only need to multiply the input by the expected value of the Bernoulli distribution 1-p. can. Dropout has obvious effects on the forward neural network, but it is difficult to achieve good results when applied to a recurrent neural network. The dropout taken by the author in this paper does not change over time, ie for different moments in a sequence, Bernoulli distributions that produce dropouts are shared, while in the inference phase, they are still multiplied by the expected value of the Bernoulli distribution 1-p. . The author takes this variant of the dropout in both the convolutional and looping layers, and the standard dropout in the full-connection layer. 3. Experiment details The data sets taken by the authors are LibriSpeech and WSJ. The feature input to the model is the spectrogram of the speech, with 20ms as a frame and a step length of 10ms. At the same time, the authors performed two levels of normalization of the features, namely, normalizing the spectrograms to a distribution with mean 0 standard deviation of 1 and performing the same normalization on each feature dimension, but this feature dimension The normalization is based on the statistics of the overall training set. In the data enhancement part, the author's enhancement parameters based on tempo are uniformly distributed from (0.7, 1.3), pitch-based enhancement parameters are uniformly distributed (-500, 500), and signal to noise ratio is added when Gaussian white noise is added. Controlled at 10-15 dB, at the same time in adjusting the speed, the author used 0.9, 1.0 and 1.1 as the adjustment coefficient. Incorporating all the data enhancement techniques above, the performance of the model increases by 20% compared to the baseline without these techniques. Dropout also improves the performance of the model. The dropout probability author sets 0.1 for data, 0.2 for convolutional layer, 0.3 for all loops and full joins, and 22.43% for model performance with dropout, combined with dropout With data enhancement, the overall performance of the model increased by 23.39%. 4. Summary This article should summarize data enhancement and regularization techniques in speech recognition. Although experimental data sets are relatively short data sets, these data sets are also very important for us to deploy an actual speech recognition system. For Chinese Mandarin speech recognition, whether it is the speaking speed or intonation of different people or the accent of a Mandarin speaker in different places, the difficulty of speech recognition is very large. If you want to collect the spoken Mandarin from different people in different places, The corpus is very unrealistic for small companies or small teams. Therefore, how to build a powerful corpus that can simulate the distribution of different accents in various parts of the country based on limited common discourse materials using data reinforcement algorithms is a practical problem that has to be faced, and solving this problem can actually be significant. To enhance the robustness of speech recognition. Easy Electronic Technology Co.,Ltd , https://www.pcelectronicgroup.com