Linux process concept and process communication application scenario
The concept of process
The process is the concept of the operating system. Whenever we execute a program, a process is created for the operating system. In the process, resources are allocated and released. It can be considered that the process is an execution of a program.
The concept of process communication
· Process user space is independent of each other, and generally cannot access each other. However, in many cases, processes need to communicate with each other to complete a certain function of the system. Processes coordinate their behavior by communicating with the kernel and other processes.
Process communication application scenario
Data transmission: A process needs to send its data to another process, and the amount of data sent is between one byte and several megabytes.
Shared data: multiple processes want to manipulate shared data, one process to modify the shared data, other processes should immediately see.
Notification events: A process needs to send a message to another or group of processes notifying it (they) that something has happened (if the process is to be notified when the process terminates).
Resource sharing: sharing the same resources among multiple processes. In order to do this, the kernel needs to provide locking and synchronization mechanisms.
Process control: Some processes want to completely control the execution of another process (such as the Debug process). At this time, the control process hopes to be able to intercept all the traps and exceptions of another process, and can know its status change in time.
Process communication
Pipe:
The pipeline includes three types:
· Common pipeline PIPE: There are usually two kinds of restrictions, one is simplex, which can only be transmitted in one direction; the other is that it can only be used between parent and child or brother processes.
· Stream pipe s_pipe: Removes the first type of restriction, which is half-duplex. It can only be used between parent and child or siblings and can be transferred in both directions.
Named Pipes: name_pipe: Removes the second restriction and allows communication between many unrelated processes.
Semaphore:
Semaphores are counters that can be used to control the access of multiple processes to shared resources. It is often used as a locking mechanism to prevent a process from accessing a shared resource when other processes access it. Therefore, it is mainly used as a synchronization method between processes and between different threads in the same process.
Message queue:
Message queues are linked lists of messages, stored in the kernel and identified by message queue identifiers. Message queuing overcomes the shortcomings of less signaling information, the ability of the pipeline to carry only unformatted byte streams, and the limited buffer size.
Signal (sinal):
· Signals are a more complex form of communication used to inform the receiving process that an event has occurred.
Shared memory :
Shared memory maps memory that can be accessed by other processes. This shared memory is created by one process but accessible by multiple processes. Shared memory is the fastest IPC method. It is specially designed for the low efficiency of communication between other processes. It is often used in conjunction with other communication mechanisms, such as signals, to achieve synchronization and communication between processes.
Socket :
· The socket is also an inter-process communication mechanism. Unlike other communication mechanisms, it can be used for process communication between different machines.
The principle of communication between processes
pipeline
How the pipeline communicates
A pipeline is a buffer managed by the kernel, which is equivalent to a note that we place in memory. One end of the pipeline is connected to the output of a process. This process will put information into the pipeline. The other end of the pipe is connected to the input of a process that extracts the information that was put into the pipe. A buffer does not need to be large, it is designed to be a circular data structure so that the pipeline can be recycled. When there is no information in the pipe, the process that reads from the pipe waits until the process on the other side puts information. When the pipe is filled with information, the process that tries to put information waits until the process on the other side retrieves the information. When both processes are terminated, the pipeline automatically disappears.
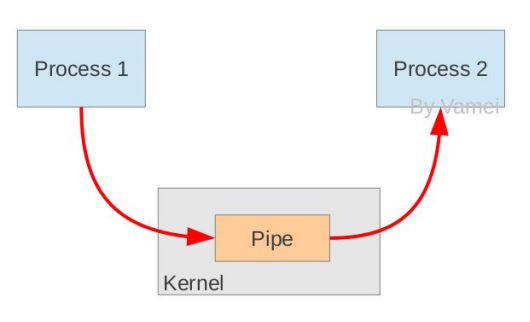
How the pipeline is created
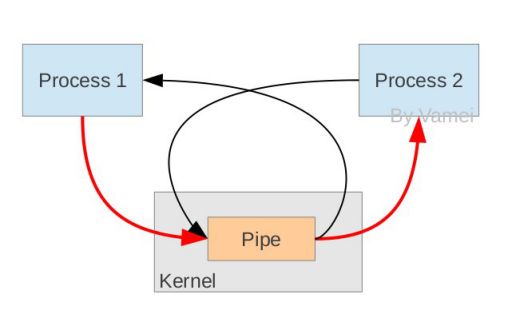
In principle, the pipeline is built using a fork mechanism so that two processes can connect to the same PIPE. At the beginning, the two arrows above are connected to the same process Process 1 (the two arrows connected to Process 1). When the fork copy process, these two connections are also copied to the new process (Process 2). Each process then closes a connection it does not need (two black arrows are closed; Process 1 closes the input connection from the PIPE, Process 2 closes the output to the PIPE connection), so that the remaining red connection constitutes PIPE as shown above.
Implementation details of pipeline communication In Linux, the implementation of the pipeline does not use a dedicated data structure, but with the help of the file system file structure and VFS index node inode. This is accomplished by pointing the two file structures to the same temporary VFS index node, which in turn points to a physical page. As shown below
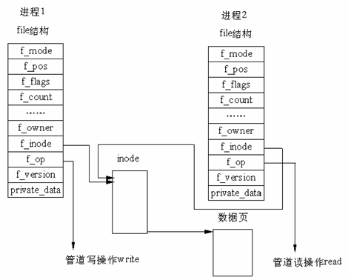
There are two file data structures, but they define different file operation process addresses, one of which is the address of the process that writes data to the pipe, and the other is the address of the process that reads data from the pipe. In this way, the system call of the user program is still the usual file operation, and the kernel uses this abstraction mechanism to implement the special operation of the pipe.
Reading and writing about pipes
The source code for the pipeline implementation is in fs/pipe.c. There are many functions in pipe.c, of which two are more important, namely the pipe read function pipe_read() and the pipe write function pipe_wrtie(). The pipe write function writes data by copying bytes to the physical memory pointed to by the VFS index node, while the pipe read function reads data by copying bytes in physical memory. Of course, the kernel must use certain mechanisms to synchronize access to the pipeline. For this purpose, the kernel uses locks, wait queues, and signals.
When the write process writes to the pipe, it uses the standard library function write(). The system can find the file structure of the file according to the file descriptor passed by the library function. The file structure specifies the address of the function (ie, write function) used to perform the write operation. The kernel then calls this function to complete the write operation. The write function must first check the information in the VFS index node before writing data to memory, and the actual memory copy work can only be performed when the following conditions are met:
· There is enough space in memory to accommodate all the data to be written;
· The memory is not locked by the reader.
If the above conditions are satisfied at the same time, the write function first locks the memory and then copies the data from the write process's address space to the memory. Otherwise, the write process sleeps in the waiting queue of the VFS index node. Next, the kernel calls the scheduler, and the scheduler selects other processes to run. The write process is actually in an interruptible wait state. When there is enough space in the memory to hold the write data or the memory is unlocked, the read process will wake up the write process. At this time, the write process will receive a signal. When the data is written to memory, the memory is unlocked, and all read processes sleeping at the index node are awakened.
Pipeline read and write processes are similar. However, processes can return error messages immediately when there is no data or memory is locked, rather than blocking the process, depending on the open mode of the file or pipe. Conversely, the process can sleep in the waiting queue of the inode waiting for the write process to write data. After all the processes have completed the pipeline operation, the index node of the pipeline is discarded, and the shared data page is also released.
Linux function prototype
#include
Int pipe(int filedes[2]);
Filedes[0] is used to read data, and must be closed when reading: close(filedes[1]);
Filedes[1] is used to write data and must be closed when writing. ie close(filedes[0]).
Program Example:
Int main(void)
{
Int n;
Int fd[2];
Pid_t pid;
Char line[MAXLINE];
If(pipe(fd) 0){ /* First create a pipe to get a pair of file descriptors */
Exit(0);
}
If((pid = fork()) 0) /* The parent process copies the file descriptor to the child process */
Exit(1);
Else if(pid > 0){ /* The parent process writes */
Close(fd[0]); /* Closes the read descriptor */
Write(fd[1], "hello world", 14);
}
Else{ /* Subprocess read */
Close(fd[1]); /* Close the write end */
n = read(fd[0], line, MAXLINE);
Write(STDOUT_FILENO, line, n);
}
Exit(0);
}
Named pipe
Because of the fork-based mechanism, the pipeline can only be used between parent and child processes, or between two child processes that have the same ancestor (between related processes). To solve this problem, Linux provides a FIFO connection process. FIFO is also called named PIPE.
Principle of realization
FIFO (First in, First out) is a special file type that has a corresponding path in the file system. When a process opens the file as read (r), and another process opens the file as write (w), the kernel will create a pipeline between the two processes, so the FIFO is actually also from the kernel Management, not dealing with hard disks. The reason why it is called FIFO is that the pipeline is essentially a first-in-first-out queue data structure. The earliest data put into the queue is read first, thus ensuring the order of information exchange. FIFO only borrows the file system (named pipe is a special type of file, because everything in Linux is a file, it exists as a file name in the file system.) to name the pipe. The write mode process writes to the FIFO file, while the read mode process reads from the FIFO file. When the FIFO file is deleted, the pipe connection disappears. The advantage of FIFO is that we can identify the pipe through the path of the file, so that the connection between the process of the unrelated process is established
Function prototype:
#include #include #include
Int mkfifo(const char *filename, mode_t mode);int mknode(const char *filename, mode_t mode | S_IFIFO, (dev_t) 0 );
Where filename is the name of the file to be created, mode indicates the permission bits to be set on the file, and the type of file to be created (in this case, S_IFIFO), where dev is a value to use when creating device special files. Therefore, it has a value of 0 for FIFO files.
Program Example:
#include #include #include #include #include
Int main()
{
Int res = mkfifo("/tmp/my_fifo", 0777);
If (res == 0)
{
Printf("FIFO created/n");
}
Exit(EXIT_SUCCESS);
}
signal
What is the semaphore
In order to prevent a series of problems caused by multiple programs accessing a shared resource at the same time, we need a method. For example, there can be only one critical area where the execution thread accesses the code at any one time. A critical area means that code that performs data updates needs to be executed exclusively. The semaphore can provide such an access mechanism so that only one thread in a critical zone can access it at a time, that is, the semaphore is used to tune the process's access to the shared resource.
The semaphore is a special variable. The program accesses it atomic operations, and only allows it to wait (that is, P (signal variables)) and send (that is, V (signal variables)) information operations. The simplest semaphore is a variable that can only take 0 and 1. This is also the most common form of semaphore, called the binary semaphore. The number of semaphores that can take a number of positive integers is called a universal semaphore.
How semaphores work
Since the semaphore can only wait and send signals in two operations, namely P(sv) and V(sv), their behavior is like this:
P(sv): If sv is greater than zero, subtract 1 from it; if its value is zero, suspend execution of the process
· V(sv): If there is another process that is suspended due to waiting for sv, let it resume running. If there is no process waiting for sv to hang, add it to 1.
For example, if two processes share a semaphore sv, once one of the processes performs a P(sv) operation, it will get the semaphore and can enter the critical zone, decrementing sv. The second process will be prevented from entering the critical region because when it tries to execute P(sv), sv is 0, it will be suspended waiting for the first process to leave the critical region and perform V(sv) to release the semaphore At this point, the second process can resume execution.
Linux semaphore mechanism
Linux provides a set of well-designed semaphore interfaces to operate on signals. They are not just for binary semaphores. These functions are described below, but please note that these functions are used to group semaphores. The value of the operation. They are declared in the header file sys/sem.h.
Semget function
Its role is to create a new semaphore or get an existing semaphore. The prototype is:
Int semget(key_t key, int num_sems, int sem_flags);
The first parameter key is an integer value (the only non-zero), an unrelated process can access a semaphore through it, it represents a resource that the program may use, the program accesses all semaphores indirectly, the program First by calling the semget function and providing a key, the system generates a corresponding signal identifier (the return value of the semget function). Only the semget function uses the semaphore key directly. All other semaphore functions use the semget function. Semaphore identifier. If multiple programs use the same key value, the key is responsible for coordinating the work.
The second parameter, num_sems, specifies the number of semaphores needed. Its value is almost always 1.
The third parameter, sem_flags, is a set of flags. When you want to create a new semaphore when the semaphore does not exist, you can do a bitwise OR operation with the value IPC_CREAT. With the IPC_CREAT flag set, no error will occur even if the given key is an existing semaphore key. IPC_CREAT | IPC_EXCL can create a new, unique semaphore and return an error if the semaphore already exists.
The semget function successfully returns a corresponding signal identifier (non-zero), failing to return -1.
Semop function
Its role is to change the value of the semaphore. The prototype is:
Int semop(int sem_id, struct sembuf *sem_opa, size_t num_sem_ops);
· 1
Sem_id is the semaphore identifier returned by semget. The sembuf structure is defined as follows:
Struct sembuf{
Short sem_num ;// It is 0 unless a set of semaphores is used
Short sem_op;// The data that the semaphore needs to change in one operation, usually two numbers, one is -1, that is, P (wait) operation,
//One is +1, that is V (send signal) operation.
Short sem_flg;//usually SEM_UNDO, which allows the operating system to track the signal,
/ / And when the process terminates without releasing the semaphore, the operating system releases the semaphore
};
Semctl function
Int semctl(int sem_id, int sem_num, int command, ...);
· 1
If there is a fourth parameter, it is usually a union semum structure defined as follows:
Union semun{
Int val;
Struct semid_ds *buf;
Unsigned short *arry;
};
The first two parameters are the same as in the previous function. The command is usually one of the following two values. SETVAL: Used to initialize the semaphore to a known value. p This value is set by the val member in union semun. Its purpose is to set the semaphore before it is used for the first time.
IPC_RMID: Used to delete a semaphore identifier that no longer needs to be used.
message queue
What is message queue
The message queue is a linked list of messages, including the Posix message queue system V message queue. A process with sufficient privileges can add messages to the queue, and a process with read privileges can read the messages in the queue. The message queue overcomes the shortcomings of less information carrying information, pipelines can only carry unformatted byte streams, and the buffer size is limited. Message queues persist with the kernel.
Each message queue has a queue header, described by the structure struct msg_queue. The head of the queue contains a large amount of information of the message queue, including the message queue key value, user ID, group ID, the number of messages in the message queue, and so on, and even the ID of the most recent reading and writing process of the message queue. Readers can access this information and can also set some of them.
The structure msg_queue is used to describe the message queue header and exists in the system space:
Struct msg_queue {
Struct kern_ipc_perm q_perm;
Time_t q_stime; /* last msgsnd time */
Time_t q_rtime; /* last msgrcv time */
Time_t q_ctime; /* last change time */
Unsigned long q_cbytes; /* current number of bytes on queue */
Unsigned long q_qnum; /* number of messages in queue */
Unsigned long q_qbytes; /* max number of bytes on queue */
Pid_t q_lspid; /* pid of last msgsnd */
Pid_t q_lrpid; /* last receive pid */
Struct list_head q_messages;
Struct list_head q_receivers;
Struct list_head q_senders;
};
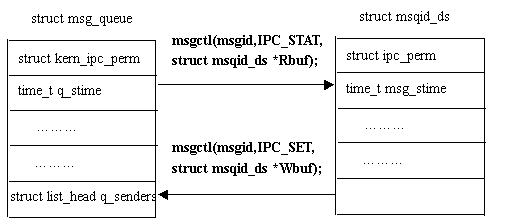
The structure msqid_ds is used to set or return message queue information, which exists in user space:
Struct msqid_ds {
Struct ipc_perm msg_perm;
Struct msg *msg_first; /* first message on queue,unused */
Struct msg *msg_last; /* last message in queue,unused */
__kernel_time_t msg_stime; /* last msgsnd time */
__kernel_time_t msg_rtime; /* last msgrcv time */
__kernel_time_t msg_ctime; /* last change time */
Unsigned long msg_lcbytes; /* Reuse junk fields for 32 bit */
Unsigned long msg_lqbytes; /* ditto */
Unsigned short msg_cbytes; /* current number of bytes on queue */
Unsigned short msg_qnum; /* number of messages in queue */
Unsigned short msg_qbytes; /* max number of bytes on queue */
__kernel_ipc_pid_t msg_lspid; /* pid of last msgsnd */
__kernel_ipc_pid_t msg_lrpid; /* last receive pid */
};
Message Queue and Core Contact
The following figure illustrates how the kernel and message queues are linked:
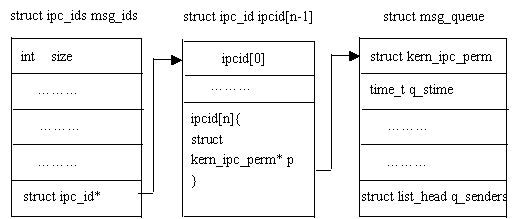
From the above figure, we can see that the global data structure struct ipc_ids msg_ids can access the first member of each message queue header: struct kern_ipc_perm; and each struct kern_ipc_perm can correspond to a specific message queue because in this structure, There is a key_t type member key, and the key uniquely identifies a message queue. The kern_ipc_perm structure is as follows:
Struct kern_ipc_perm{ // The global data structure msg_ids of the queued message queue in the kernel can access this structure;
Key_t key; //this key value uniquely corresponds to a message queue
Uid_t uid;
Gid_t gid;
Uid_t cuid;
Gid_t cgid;
Mode_t mode;unsigned long seq;
}
Message Queue Operation
The kernel persistence of opening or creating a message queue queue requires that each message queue has a unique system-wide corresponding key value. Therefore, to obtain the description word of a message queue, you only need to provide the key value of the message queue.
Note: The message queue description word is generated by a system-wide unique key value, and the key value can be seen as a path within the corresponding system.
Read and write operations
Message reading and writing operations are very simple. For developers, each message is similar to the following data structure:
Struct msgbuf{long mtype;char mtext[1];
};
The mtype member represents the message type. An important basis for reading a message from the message queue is the type of the message; mtext is the message content, but of course the length is not necessarily 1. Therefore, for sending messages, first preset a msgbuf buffer and write the message type and content, and call the corresponding send function; for read messages, first allocate such a msgbuf buffer, and then read the message. Into the buffer can be.
· Get ​​or set the message queue properties:
The message queue information is basically stored in the message queue header. Therefore, a structure similar to the message queue header can be allocated to return the attributes of the message queue; the data structure can also be set.
signal
Signal nature
The signal is a simulation of the interrupt mechanism at the software level. In principle, a process receives a signal and the processor receives an interrupt request can be said to be the same. The signal is asynchronous, a process does not have to wait for any signal to arrive, in fact, the process does not know when the signal arrives.
The signal is the only asynchronous communication mechanism in the inter-process communication mechanism and can be seen as an asynchronous notification that informs the receiving signal of what happened in the process. The signal mechanism is more powerful after real-time extension of POSIX. In addition to the basic notification function, it can also pass additional information.
Source of signal
Signal events occur from two sources: hardware sources (such as when we press a keyboard or other hardware failure); software sources, the most commonly used system functions for sending signals are kill, raise, alarm, setitimer, and sigqueue functions. Software sources also include Some illegal operations and other operations.
Type of signal
· Signals can be classified from two different classification perspectives: (1) Reliability: Reliable signals and unreliable signals; (2) Relationship with time: Real-time signals and non-real-time signals.
Reliable signals and unreliable signals
Unreliable signal
The Linux signaling mechanism is basically inherited from Unix systems. The signal mechanism in early Unix systems was relatively simple and primitive. Later, some problems were exposed in practice. Therefore, signals that were built on earlier mechanisms were called "unreliable signals" and the signal value was smaller than SIGRTMIN (Redhat 7.2, SIGRTMIN Signals with =32, SIGRTMAX=63) are all unreliable signals. This is the source of the "unreliable signal." Its main problems are:
• Each time the process processes a signal, it sets the response to the signal as the default action. In some cases, this will result in error handling of the signal; therefore, if the user does not want such an operation, it will need to call signal() again at the end of the signal processing function to re-install the signal.
·
The signal may be lost Therefore, the unreliable signal in the early Unix mainly refers to the process may make a wrong reaction to the signal and the signal may be lost.
Linux supports unreliable signals, but it improves the unreliable signal mechanism: After calling a signal processing function, it is not necessary to re-invoke the signal's installation function (the signal installation function is implemented on a reliable mechanism). Therefore, the problem of unreliable signals under Linux mainly means that the signal may be lost.
Reliable signal
With the development of time, practice has proved that it is necessary to improve and expand the original mechanism of the signal, and strive to achieve a "reliable signal." Since the originally defined signal has many applications, it is not good to make any changes, and eventually we have to add some new signals, and define them as reliable signals at the beginning. These signals support queuing and will not be lost.
Signals with signal values ​​between SIGRTMIN and SIGRTMAX are reliable signals, and reliable signals overcome the problem of possible signal loss. Linux supports the early signal() signal setup function and supports the signalling function kill() while supporting the new version of the signal setup function, sweep(), and the signalling function sigqueue().
Note: A reliable signal is a new signal added later (the signal value is between SIGRTMIN and SIGRTMAX); an unreliable signal is a signal with a signal value less than SIGRTMIN. The reliability and unreliability of the signal are only related to the signal value, and are independent of the signal sending and installation functions.
Real-time and non-real-time signals
• Non-real-time signals do not support queuing and are all unreliable signals. The numbers are 1-31, 0 is an empty signal; real-time signals all support queuing and are reliable signals.
Process response to signal
Ignore the signal, that is, do nothing to the signal, of which, there are two signals can not be ignored: SIGKILL and SIGSTOP;
· Capture signal. Define the signal processing function, when the signal occurs, execute the corresponding processing function;
· By default, Linux specifies default actions for each signal
Note: The default reaction of the process to real-time signals is process termination.
Signal sending and installation
The main functions for sending signals are: kill(), raise(), sigqueue(), alarm(), setitimer(), and abort().
· If the process wants to process a signal, then install the signal in the process. The installation signal is mainly used to determine the mapping relationship between the signal value and the process's action on the signal value, ie which signal the process will process; what kind of operation will be performed when the signal is passed to the process.
Note: inux has two main functions for signal installation: signal(), sigaction(). Signal() is implemented on the basis of a reliable signal system call and is a library function. It has only two parameters, does not support signaling information, is mainly used for the installation of the first 32 non-real-time signals; sigaction () is a relatively new function (implemented by two system calls: sys_signal and sys_rt_sigaction), there are three parameters , support for signalling information, mainly used with the sigqueue () system call, of course, sigaction () also supports non-real-time signal installation. Sigaction () is better than signal () mainly reflected in the support signal with parameters.
Shared memory
Shared memory is arguably the most useful way to communicate between processes and is the fastest form of IPC. It is designed for the lower operating efficiency of other communication mechanisms. The meaning of the shared memory of two different processes A and B is that the same physical memory is mapped to the process address space of processes A and B respectively. Process A can immediately see the update of data in shared memory by process B, and vice versa. Because multiple processes share the same memory area, it will inevitably require some sort of synchronization mechanism, mutual exclusion locks and semaphores.
System V shared memory principle
The data that needs to be shared between processes is placed in an IPC shared memory area. All processes that need to access the shared area must map the shared area to the address space of the process. System V Shared Memory Acquires or creates an IPC shared memory area through shmget and returns the corresponding identifier. The kernel ensures that shmget obtains or creates a shared memory area and initializes the corresponding shmid_kernel structure of the shared memory area. At the same time, the kernel creates and opens a file with the same name in the special file system shm, and establishes the file in memory. The corresponding dentry and inode structure, the newly opened file does not belong to any process (any process can access the shared memory area). All of this is done with the shmget system call.
System V Shared Memory API
Shmget() is used to get the ID of the shared memory area. If the specified shared area does not exist, the corresponding area is created. Shmat() maps the shared memory area to the calling process's address space so that the process can easily access the shared area. The shmdt() call is used to release the process's mapping to the shared memory area. Shmctl implements control operations on the shared memory area.
Socket
It first appeared in the UNIX system and was the main method of information transfer in the UNIX system.
Socket related concepts
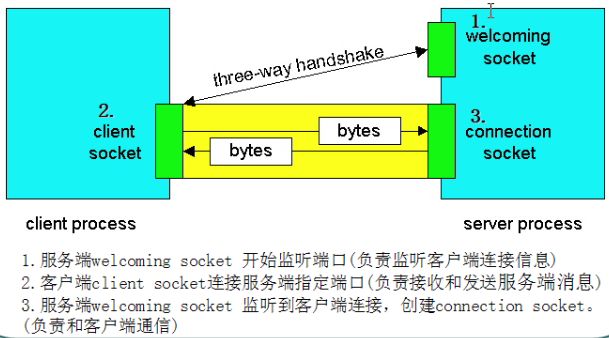
Two basic concepts: customer and service. When SOCKET communication is required between two applications, first a SOCKET connection needs to be established between the two applications (possibly on the same machine or on a different machine).
The party making the call connection request is the client side. Before the client can call the connection request, it must know where the service is. Therefore, it is necessary to know the IP address or the machine name of the server on which the server is located. If the client and the service provider have an agreement beforehand, the agreement is PORT (port number). In other words, the client can call the service party through the unique method of determining the IP address of the server or the machine name and port number of the server.
The party accepting the call connection request becomes the service party. Before the customer calls, the service must be listening and listen for any customer requests to establish a connection. Once the connection request is received, the service provider can establish or reject the connection according to the situation. When the client's message arrives at the service port, an event is triggered automatically. As soon as the service party takes over the event, it can accept the message from the client.
Socket type
· Streamed Socket (STREAM): is a connection-oriented Socket, for connection-oriented TCP service applications, secure, but inefficient;
Datagram Socket (DATAGAM): A connectionless Socket that corresponds to a connectionless UDP service application. Uneasy (lost, out of order, analyzed reordering and retransmission at the receiving end), but efficient.
Socket general application mode (server and client)
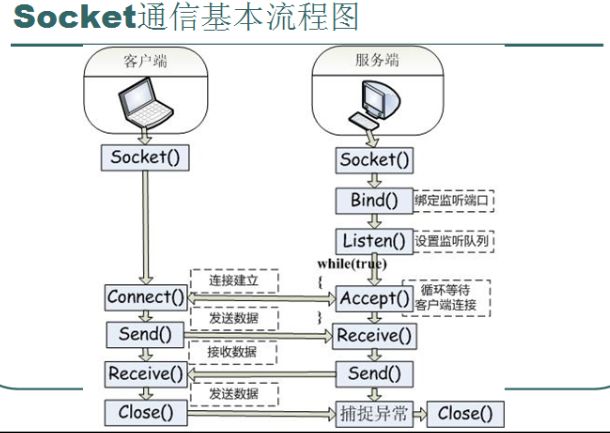
Socket communication basic flow chart
Special requirements for medical power wire harness:
At present, most medical equipment adopts switching power supply. With the development of electronic technology, switching power supply is not only greatly reduced in size and weight, but also greatly reduced in energy consumption and improved reliability. Medical diagnostic, measurement and treatment equipment using AC power equipment, may cause leakage currents due to improper grounding and electrical insulation, exposing patients and medical personnel to potential hazards such as electric shock, burns, damage to internal organs, and arrhythmias.
In view of the special use environment of medical equipment, medical power Wire Harness has more stringent requirements in terms of safety and reliability.
Reliable power supply is the basis to ensure the long-term use of medical equipment. Kable-X provides power Cable Assembly and power extension cord assemblies for many internationally renowned companies. The wiring harnesses are widely used in ventilators, defibrillators, surgical equipment, health equipment and other medical devices that are related to life safety. Therefore, we pay special attention to the quality of our products. Kable-X is a manufacturer certified by UL and ISO. Our production is also strictly in accordance with the IPC/WHMA-A-620 standard.
We produce a large number of Medical Cable Assembly, including Medical Power Wire Harness, Medical Defibrillator Wire Harness and Medical Aid Equipment Wire Harness.
Welcome to contact our sales and engineers to discuss your products together!

Medical Power Wire Harness,Cable Assembly Flat,Custom Flat Cable,Electrical Harness Assembly
Kable-X Technology (Suzhou) Co., Ltd , https://www.kable-x-tech.com